Decision Tree in Machine Learning: Complete Guide
Welcome to this definitive guide on the highly intuitive and interpretable decision tree in machine learning. If you are exploring how algorithms can make logic-based choices, mastering the decision tree algorithm in machine learning is an absolute must. In this tutorial, we will uncover how it works, explore its mathematical foundations, and write standard Python code to deploy it.
1. What is a Decision Tree in AI & Machine Learning?
When studying artificial intelligence, the decision tree machine learning algorithm is often one of the first and most widely utilized models you encounter. At its core, a decision tree in ai is a supervised learning technique that mimics human decision-making. It operates by breaking down a data set into smaller and smaller subsets while simultaneously developing an associated logic-based flow.
Due to its simplicity and high interpretability, the decision tree in ml is extensively used to map out consequences, resource costs, and utility values, making it highly requested for business intelligence analysts and data scientists alike.
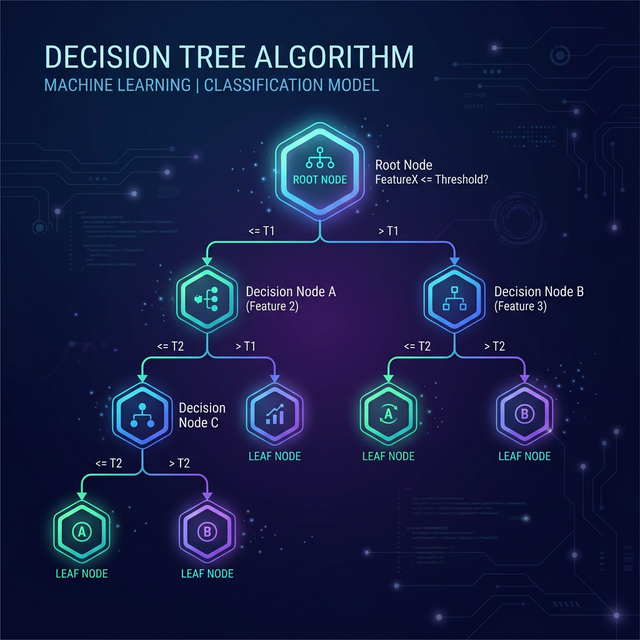
2. Understanding the Decision Tree Diagram
To fully grasp the flow of the algorithm, you must visualize the decision tree diagram. The architecture consists of three main components:
- Root Node: This is the very top of the tree. It represents the entire population or dataset, which gets divided into two or more homogeneous sets.
- Decision Nodes (Branches): When a sub-node splits into further sub-nodes, it is called a decision node. These represent a test or condition on a specific attribute (e.g., "Is Age > 30?").
- Leaf Nodes (Terminal Nodes): Nodes that do not split any further are leaf nodes. These represent the final predicted outcome or class label.
3. Decision Tree Classifier vs. Decision Tree Regression
The beauty of the decision tree algorithm is its versatility. It can be utilized for two primary tasks:
- Decision Tree Classifier: Used when the target variable is categorical (discrete). For example, predicting whether a customer will "Churn" or "Not Churn," or diagnosing a patient as "Healthy" or "Sick". The leaf nodes represent the final category.
- Decision Tree Regression: Used when the target variable is continuous (numerical). For example, predicting the exact dollar price of a house or visualizing future stock prices. The leaf node represents the average (mean) value of the continuous target variable falling into that region.
4. The Math Behind It: Entropy, Information Gain, and Gini Impurity
How does the machine know which feature to split the data on first? To create the most efficient tree, the algorithm employs mathematical metrics to identify the best feature that splits the data into the purest possible subsets.
Entropy is a measure of randomness or impurity in the dataset. A completely pure set has an entropy of 0. Before splitting, the algorithm calculates the total entropy.
Information Gain is the mathematical decrease in entropy after a dataset is split on an attribute. The formula is simply:
Furthermore, the standard CART (Classification and Regression Trees) algorithm generally relies on Gini Impurity, which measures the probability of incorrectly classifying a randomly chosen element from the dataset. It runs extremely fast and efficiently compared to Entropy calculation because it avoids logarithmic scales.
5. Decision Tree in Data Mining & Analytics
Conducting profound decision tree analysis is a foundational aspect of professional decision tree data mining. Corporations utilize decision tree analytics extensively because the models output an easily digestible, "white-box" set of rules.
For example, a bank might run millions of customer transaction histories through a Decision Tree model to build an automatic credit approval system. Management can literally look at the generated decision tree diagram and understand: "If Income > $50k AND Credit Score > 700, then Approve." This transparency is legally required in many financial and medical applications.
6. Practical Decision Tree Example Source Code
To crystallize your understanding, let's look at a concrete decision tree example
utilizing Python and scikit-learn.
Here we will build a decision tree classifier simulating a product purchasing scenario based on user Age and Estimated Salary.
# 1. Import required libraries and modules
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 2. Simulate User Data: [Age, Estimated Salary in $] -> Output 1 (Bought) or 0 (Not Bought)
X = np.array([[22, 25000], [25, 30000], [47, 85000], [52, 105000], [46, 50000], [35, 65000], [19, 15000], [60, 150000]])
y = np.array([0, 0, 1, 1, 1, 0, 0, 1])
# 3. Train-Test Split (75% Training, 25% Testing)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# 4. Initialize the Decision Tree Classifier (Using entropy criterion)
classifier = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)
# 5. Fit the model exclusively to training data
classifier.fit(X_train, y_train)
# 6. Make probability predictions
predictions = classifier.predict(X_test)
# 7. Evaluate Performance Status
print(f"Decision Tree Accuracy: {accuracy_score(y_test, predictions) * 100}%")
# 8. (Optional) Visualize the generated mathematical Tree Structure
plt.figure(figsize=(10,6))
plot_tree(classifier, feature_names=['Age', 'Salary'], class_names=['No', 'Yes'], filled=True)
plt.show()Conclusion
The decision tree in machine learning is a robust, widely applicable algorithm suitable for both logical categorical predictions and continuous numeric regressions. While deep neural networks might provide fractions of a percent higher accuracy in giant datasets, nothing beats the stunning interpretability, lack of required data scaling, and overall agility derived from deep decision tree analysis!
Discussion