Naive Bayes Classifier in Machine Learning: Complete Guide
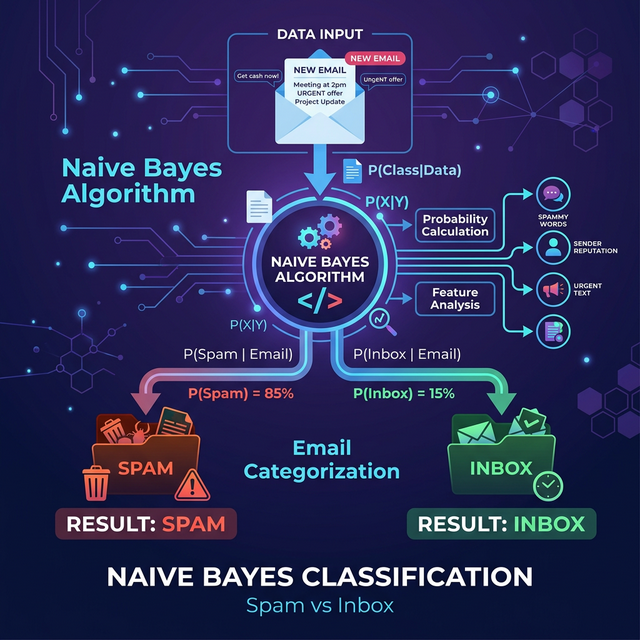
When you browse your email inbox, how does the system instantly know which messages belong in the primary inbox and which belong in the Spam folder? The answer almost always relies on the naive bayes algorithm. Let us dive deep into the magnificent world of conditional probability and text classification.
1. What is the Naive Bayes Classifier?
The naive bayes classifier is an elegant supervised machine learning algorithm fundamentally rooted in Bayes' Theorem. It calculates naive bayes probability to predict the class of an unknown data point based on prior knowledge of conditions that might be related to that class.
It is predominantly used in Natural Language Processing (naive bayes nlp) for high-dimensional text datasets. It thrives on categorizing text into binary labels (Spam vs. Not Spam) or multi-class labels (Sports, Politics, Tech News).
2. Bayes' Theorem Formula
To understand the algorithm, you must understand the probability engine powering it. Bayes' Theorem calculates the probability of an event (A) occurring given that another event (B) has already occurred.
- P(A|B): The "Posterior Probability" (e.g., Probability the email is Spam, given that it contains the word 'Free').
- P(A): The "Prior Probability" (e.g., Baseline probability of any email being Spam).
- P(B|A): The "Likelihood" (e.g., Probability of seeing the word 'Free' in emails we already know are Spam).
3. Why is it called "Naive"?
The algorithm makes an incredibly loud, and often completely false, mathematical assumption: It assumes that the presence of every particular feature in a class is completely independent of the presence of any other feature.
For example, if the model sees the phrase "Free Money", it calculates the probability of the word "Free" and the probability of the word "Money" completely independently. It is totally "naive" to the fact that those two words usually appear together in a grammatical phrase. Despite this mathematically flawed assumption, the algorithm inexplicably performs astonishingly well in real-world scenarios!
4. Spam Detection Machine Learning Example
Let's run a practical spam detection machine learning implementation. Check out my live SMS Spam Detection Project to see this in action!
Below is standard Python code defining a Multinomial Naive Bayes model using the brilliant scikit-learn documentation.
# 1. Import ML and NLP modules
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report
# 2. Simulated SMS Dataset: Text Message -> Spam (1) or Ham (0)
data = {
'Text': [
"Win a FREE iPhone now! Click here",
"Hey mom, when is dinner ready?",
"URGENT: Your bank account is compromised, send details",
"Are we still meeting at 5 PM for coffee?",
"Congratulations! You won $50000 cash. Call this number",
"Can you send me the math homework?"
],
'Label': [1, 0, 1, 0, 1, 0] # 1=Spam, 0=Ham (Safe)
}
df = pd.DataFrame(data)
# 3. Train-Test Split (80/20)
X_train, X_test, y_train, y_test = train_test_split(df['Text'], df['Label'], test_size=0.33, random_state=42)
# 4. Text Vectorization (Convert words into numerical matrices)
vectorizer = CountVectorizer()
X_train_vectorized = vectorizer.fit_transform(X_train)
X_test_vectorized = vectorizer.transform(X_test)
# 5. Initialize the Naive Bayes Classifier (Multinomial is best for text counts)
nb_classifier = MultinomialNB()
# 6. Fit the Model
nb_classifier.fit(X_train_vectorized, y_train)
# 7. Predict & Evaluate
predictions = nb_classifier.predict(X_test_vectorized)
print(f"Naive Bayes Accuracy: {accuracy_score(y_test, predictions) * 100}%")
print("\nClassification Report:\n", classification_report(y_test, predictions))Conclusion
For text analytics, sentiment analysis, and recommendation systems, the Naive Bayes algorithm remains an absolute powerhouse. It trains faster than almost any other algorithm in existence because it simply calculates frequency tables rather than running complex geometric gradient descents. It scales flawlessly to millions of rows.
Discussion