Vehicle Insurance Claim Fraud Detection (ClaimGuard AI) — A Complete Project Overview
In the insurance sector, fraud costs companies billions of dollars annually. To combat this, I designed and developed ClaimGuard AI, a premium machine learning workflow and interactive dashboard designed to assess vehicle insurance claim fraud risk in real-time. Built specifically for insurance underwriters and risk auditors, this project demonstrates a complete production-grade machine learning workflow—handling severe class imbalance, deploying state-of-the-art gradient boosting classifiers, and implementing business-centric evaluation metrics like Audit Efficiency (Lift).
🚀 Key Features
- XGBoost Classifier: Powered by an optimized Gradient Boosting model built for handling high-dimensional tabular datasets.
- Imbalance-Resilient Training: Implements cost-sensitive learning (
scale_pos_weight = 15.71) to train effectively on minority fraud cases (~6% prevalence) without oversampling noise. - Operational Threshold Tuning: A global risk threshold slider allowing underwriters to tune the decision boundary in real-time, shifting focus between catching all fraud (Recall) and avoiding false alarms (Precision).
- Business-Centric Evaluation: Replaces misleading standard accuracy with Audit Efficiency (Lift), demonstrating a 2.7x efficiency multiplier over random audits at the optimal threshold.
- Interactive Streamlit UI: Sleek dark-mode interface featuring dynamic metrics, interactive risk assessment forms, and real-time feature importances.
🧠 Technologies Used
- Core Logic: Python, Pandas, NumPy
- Machine Learning: Scikit-Learn, XGBoost
- Inference Serialization: Pickle
- Application Deployment: Streamlit, Streamlit Community Cloud
📊 Performance Metrics (Test Set Evaluation)
Standard accuracy is highly misleading when evaluating class-imbalanced fraud detection (where ~94% of claims are legitimate). Below is the performance comparison across various decision thresholds:
| Decision Threshold | Recall (Fraud Caught) | Precision (Flag Accuracy) | Audit Efficiency (Lift) | Accuracy |
|---|---|---|---|---|
| 0.50 (Default) | 2.7% | 41.7% | 7.0x | 93.8% |
| 0.15 (Balanced) | 63.8% | 16.1% | 2.7x | 77.9% |
| 0.10 (High Sensitivity) | 84.3% | 14.1% | 2.4x | 68.1% |
🧠 Data Processing & Feature Engineering
- Anomaly Resolution: Identified and resolved an age data anomaly where a subset of minor policyholders were placeholder-imputed with 0 years old (mapped to 16).
- Ordinal Mapping: Standardized size, period, and tier structures (e.g., VehiclePrice, AgeOfVehicle, PastNumberOfClaims) to continuous ranks.
- Nominal Columns: Encoded high-cardinality categorical data (Make, PolicyType, DayOfWeekClaimed) using
OneHotEncoder(drop='first', handle_unknown='ignore')fitted strictly on the training set to prevent data leakage. - Dimensionality expansion: Preprocessing expands the 29 base features to 86 model features to capture non-linear relationships.
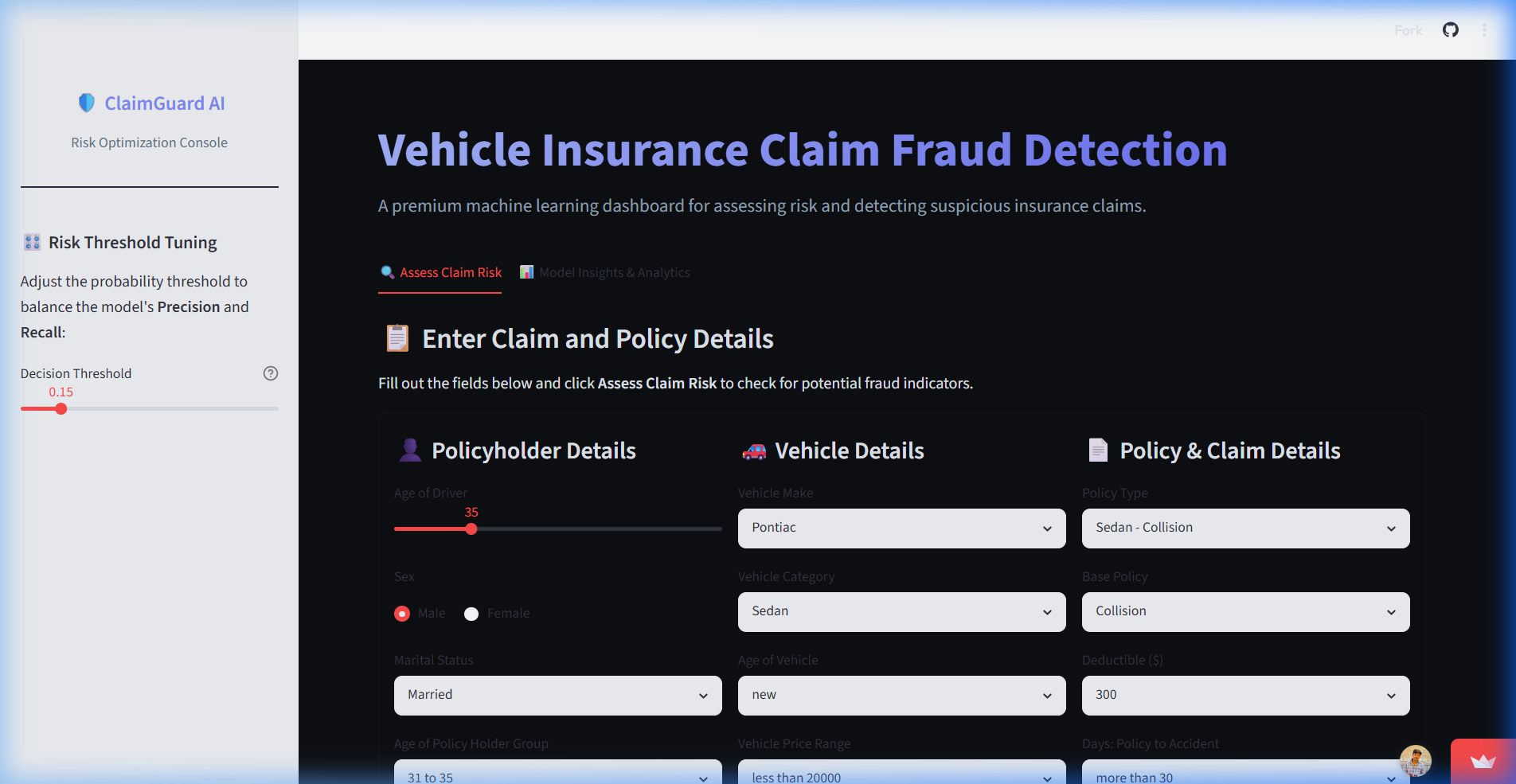
🌐 User Interface Preview
A responsive dashboard allowing quick data entry and returning clear, actionable prediction results.
🧪 Try It Live & View Code
Click here to launch the live Streamlit Dashboard
View the complete codebase on GitHub
🔗 Connect with Me
🌐 www.tauqueeralam.com
📱 LinkedIn | GitHub
View a live demo below:
View Demo
Discussion