Random Forest in Machine Learning: The Complete Guide
If you have studied our previous article defining the Decision Tree algorithm, you'll know that trees are incredibly useful but dangerously prone to overfitting. Today, we explore the definitive solution: Random Forest in machine learning. By combining hundreds of simple trees into a single, cohesive "forest," we unlock one of the most powerful algorithms in modern data science.
1. What is the Random Forest Algorithm?
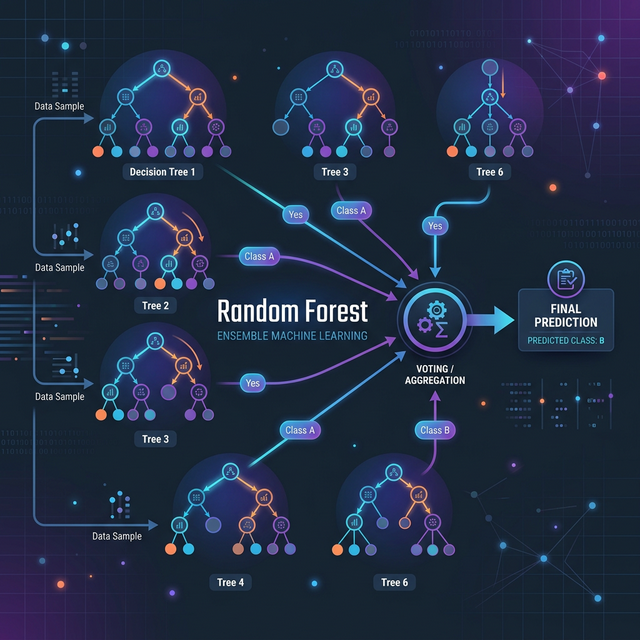
The random forest algorithm is a trademark supervised learning method used primarily for classification and regression tasks. It falls under a broader machine learning category called Ensemble Learning.
Instead of relying on a single complex model to make a decision, an ensemble method creates a vast multitude of smaller, slightly different models and aggregates their predictions to formulate a final, highly accurate output. In simpler terms, Random Forest asks a "crowd" of Decision Trees for their opinion, and the majority vote wins.
2. Random Forest Classifier vs Decision Tree: Why Upgrade?
Why not just use a standard Decision Tree? Let’s examine the monumental differences between predicting with one tree versus an entire random forest classifier vs decision tree setup:
- Overfitting: A single decision tree will often grow too deep, perfectly memorizing the training data but failing on new unseen data. By randomly training hundreds of smaller trees (which individually have high bias), a Random Forest organically averages out the errors, almost entirely eliminating overfitting.
- Variance: A single tree is highly sensitive to small variations in the dataset. A Random Forest provides incredible stability and robustness against noise.
- Accuracy: The collective "wisdom of the crowd" in a forest statistically outperforms even the best-tuned singular tree in large datasets.
3. How Does the "Forest" Work? (Bagging)
The secret mathematical ingredient inside a Random Forest is Bagging (Bootstrap Aggregating). Bagging operates in two distinct steps:
- Bootstrapping (Random Data): From your master dataset, the algorithm creates hundreds of smaller "mini-datasets" by randomly picking rows with replacement. Every single tree in the forest is trained on a slightly different, randomized slice of data.
- Feature Randomness: At every decision split inside the trees, the algorithm isn't allowed to look at all the features. It is forced to randomly pick from a small subset of features (like choosing between 'Age' or 'Income' instead of all 20 columns). This forces the trees to become completely uncorrelated and uniquely diverse.
Once trained, if you feed a new customer to the model, all 500 trees cast their vote ("Yes" or "No"), and the forest aggregates the majority vote for classification, or takes the average for continuous regression.
4. Practical Random Forest Python Example
Writing a random forest python example is extremely straightforward using the scikit-learn module's
documentation.
Below is code deploying the Random Forest algorithm to classify simulated financial data:
# 1. Import necessary ensemble libraries
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# 2. Simulate User Data: [Credit Score, Income, Debt] -> Default (1) or Paid (0)
X = np.array([[700, 50000, 1000], [600, 40000, 8000], [550, 35000, 15000], [750, 80000, 500], [620, 45000, 9000], [800, 120000, 0]])
y = np.array([0, 1, 1, 0, 1, 0])
# 3. Train-Test Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 4. Initialize Random Forest Classifier
# n_estimators dictates the number of trees in the forest (e.g., 100)
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42, max_depth=4)
# 5. Fit the forest to the training data
rf_classifier.fit(X_train, y_train)
# 6. Command the forest to make a prediction
predictions = rf_classifier.predict(X_test)
# 7. Evaluate the multi-tree accuracy
print(f"Random Forest Accuracy: {accuracy_score(y_test, predictions) * 100}%")
print("\nClassification Report:\n", classification_report(y_test, predictions))Conclusion
The random forest machine learning model combines high flexibility, incredibly simple hyperparameter tuning, and robust mathematical resistance against extreme outliers. Whenever you encounter tabular data requiring definitive categorization, Random Forest should immediately be one of your top baseline models to explore.
Discussion