Data Preprocessing in Machine Learning: Complete Guide
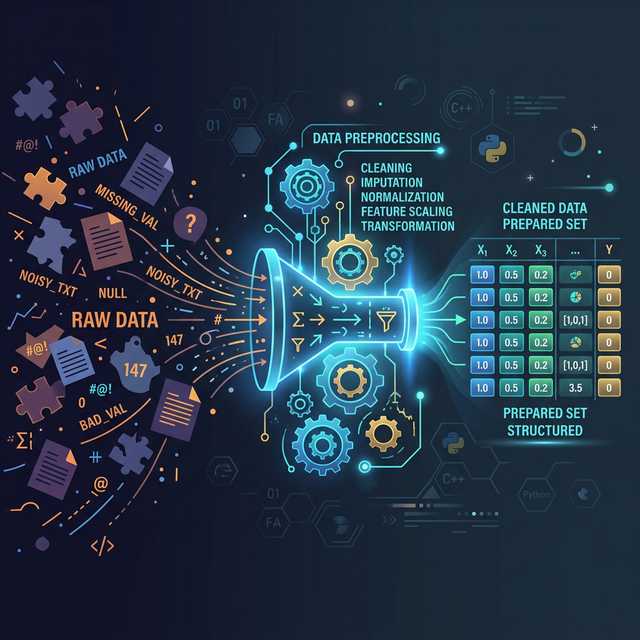
There is a golden rule in artificial intelligence: "Garbage In, Garbage Out." Before you can even think about deploying a massive Neural Network or Random Forest, your dataset must be surgically cleaned. This vital preparatory stage is known as data preprocessing in machine learning.
Raw real-world data is inherently flawed. It contains missing blank cells, raw text that algorithms can't read, and numerical values that vary wildly in scale. Let's break down the four mandatory data cleaning steps every data scientist takes.
1. Handling Missing Data (Imputation)
Algorithms will violently crash if they attempt to calculate math on an empty "NaN" (Not a Number) spreadsheet cell. To handle missing values python offers two primary solutions:
- Deletion: If your dataset has 1,000,000 rows and only 5 are missing an 'Age', simply delete those 5 rows.
- Mean Imputation: If a significant portion of data is missing, deleting rows destroys your statistical power. Instead, you calculate the mathematical Average (Mean) of the entire column and inject that number into all the blank empty spots.
2. Encoding Categorical Variables
Pure mathematics entirely governs machine learning. An algorithm does not know what the word "France" means. Therefore, we must convert all text-based categories into pure numbers.
One Hot Encoding vs Label Encoding
- Label Encoding: Assigns an arbitrary integer to every category. For example: Small = 0, Medium = 1, Large = 2. This is perfect for ordinal data (where the order inherently matters).
- One-Hot Encoding: Used for nominal data where there is no ranking (like Countries: France, Spain, Germany). It creates a brand new binary (0 or 1) column for every single country. If the row is France, the "France" column gets a 1, and the others get a 0. This prevents the algorithm from mistakenly thinking "Germany (3) is mathematically higher/better than France (1)."
3. Feature Scaling
If you feed a KNN model a dataset containing a person's exact Age (e.g., 35) and their precise Salary (e.g., $95,000), the massive $95k number will completely obliterate the smaller '35' in the mathematical geometric distance calculations. The algorithm will foolishly ignore Age completely.
Feature scaling machine learning solves this by squeezing every number into identical proportions. The two main types are:
- Standardization (StandardScaler): Scales data so that it has a mean of 0 and a standard deviation of 1. Highly recommended for Neural Networks and SVMs.
- Normalization (MinMaxScaler): Squeezes every number perfectly between 0.0 and 1.0. Excellent for data that doesn't follow a normal bell curve.
4. Comprehensive Scikit Learn Preprocessing Code
Here is what the full data preprocessing pipeline looks like using the legendary
scikit-learn library:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
# 1. Load the raw, messy dataset
# Imagine columns: [Country (Text), Age (Num), Salary (Num)] -> Purchased? [Yes/No]
df = pd.read_csv('raw_customer_data.csv')
X = df.iloc[:, :-1].values # All Independent Features
y = df.iloc[:, -1].values # The Target Answer Column
# 2. Impute Missing Values (Replace all blank 'NaN' numbers with the Column Mean)
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
X[:, 1:3] = imputer.fit_transform(X[:, 1:3])
# 3. Handle Categorical Text
# One-Hot Encode 'Country' (Column Index 0)
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder='passthrough')
X = np.array(ct.fit_transform(X))
# Label Encode the Target feature 'Purchased?' (Yes/No -> 1/0)
le = LabelEncoder()
y = le.fit_transform(y)
# 4. Train Test Split
# ALWAYS split data BEFORE scaling to prevent Data Leakage!
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 5. Feature Scaling (Standardization)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) # Only transform the test set! Never fit it!
print("Data is now 100% clean, scaled, encoded, and ready for Machine Learning!")Conclusion
In the real world, data scientists spend up to 80% of their actual time purely on scikit learn preprocessing. Writing the algorithm itself usually only takes 5 lines of code. Mastering imputation, encoding, and scaling is the true hallmark of a senior data professional.
Discussion