Supervised vs Unsupervised Learning: The Ultimate Breakdown
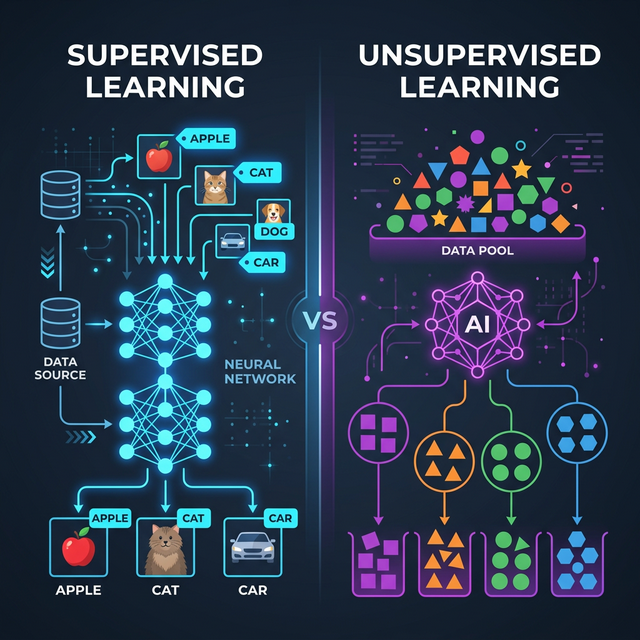
Welcome to the most fundamental junction in artificial intelligence. Whether you are building web recommendation engines or self-driving cars, you must first answer a critical question regarding your dataset: Are you using labeled data or unlabeled data? This single question defines the difference between supervised and unsupervised learning.
In this comprehensive guide, we will break down both methodologies, explore explicit supervised vs unsupervised machine learning algorithms, and summarize exactly when you should apply them to real-world datasets.
1. What is Supervised Learning? (Labeled Data)
In Supervised Learning, you act as the "supervisor" or teacher. You provide the machine learning algorithm with a heavily structured dataset that contains both the input data (features) and the correct output answers (labels). The algorithm looks at the answers, tries to guess the pattern, and mathematically corrects itself over millions of iterations until its guesses perfectly align with your provided answers.
For example, if you want a program to recognize images of Apples, you must upload 10,000 pictures of apples that a human being has explicitly tagged with the exact label "Apple."
Key Sub-categories:
- Classification: The output variable is a strict category or class (e.g., 'Spam' or 'Not Spam', 'Cat' or 'Dog'). Incredible models like the Naive Bayes Classifier, Random Forest, and Support Vector Machines (SVM) excel here.
- Regression: The output variable is a continuous numerical value. Models like Linear Regression are used to predict precise figures like House Prices or Weather Temperatures.
2. What is Unsupervised Learning? (Unlabeled Data)
In Unsupervised Learning, there is no supervisor, and there are absolutely no answers or "labels" provided. You simply dump a massive, chaotic spreadsheet of raw numerical data into the algorithm. The algorithm's job is to autonomously read the data and discover hidden mathematical structures, groupings, and patterns that human eyes could never detect.
For example, you provide a retailer's database containing millions of customer transactions without telling the machine what to look for. The machine will naturally organize the customers into 5 distinct behavioral segments based on hidden statistical similarities.
Key Sub-categories:
- Clustering: Grouping overlapping, unlabeled data based on inherent similarities. The undisputed king of this domain is K-Means Clustering.
- Dimensionality Reduction: Compressing models with 1,000 variables (like high-megapixel imagery) down to just 3 variables without losing the core contextual information. Principal Component Analysis (PCA) is widely used here.
3. The Core Differences Summarized
Let's map out the machine learning classification vs clustering dynamics clearly.
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Type Required | Strictly Labeled Data (Requires pre-existing answers) | Strictly Unlabeled Data (No pre-existing answers) |
| Primary Goal | To predict future outcomes accurately and correctly classify new data. | To discover hidden structures, correlations, and natural data groupings. |
| Complexity & Cost | Extremely high. Paying humans to manually label 100k images is very expensive. | Lower barrier to entry. Raw data is abundantly generated globally every second. |
| Model Evaluation | Extremely straightforward (You compare the model's prediction against your answer key). | Difficult and highly subjective. There is no answer key to verify against. |
| Top Algorithms | Linear/Logistic Regression, Decision Trees, KNN, Random Forest, SVM. | K-Means Clustering, DBSCAN, Hierarchical Clustering, PCA, Apriori. |
Conclusion
Both disciplines serve radically different functions within the AI technology sector. Supervised learning examples constantly power your daily life (Email Spam filters, Apple FaceID, Netflix predicting if you'll "Like" a movie). Conversely, unsupervised learning examples power the unseen back-end corporate architecture (segmenting market demographics, discovering genetic DNA sequence anomalies, and filtering out fraudulent banking IPs).
Discussion